

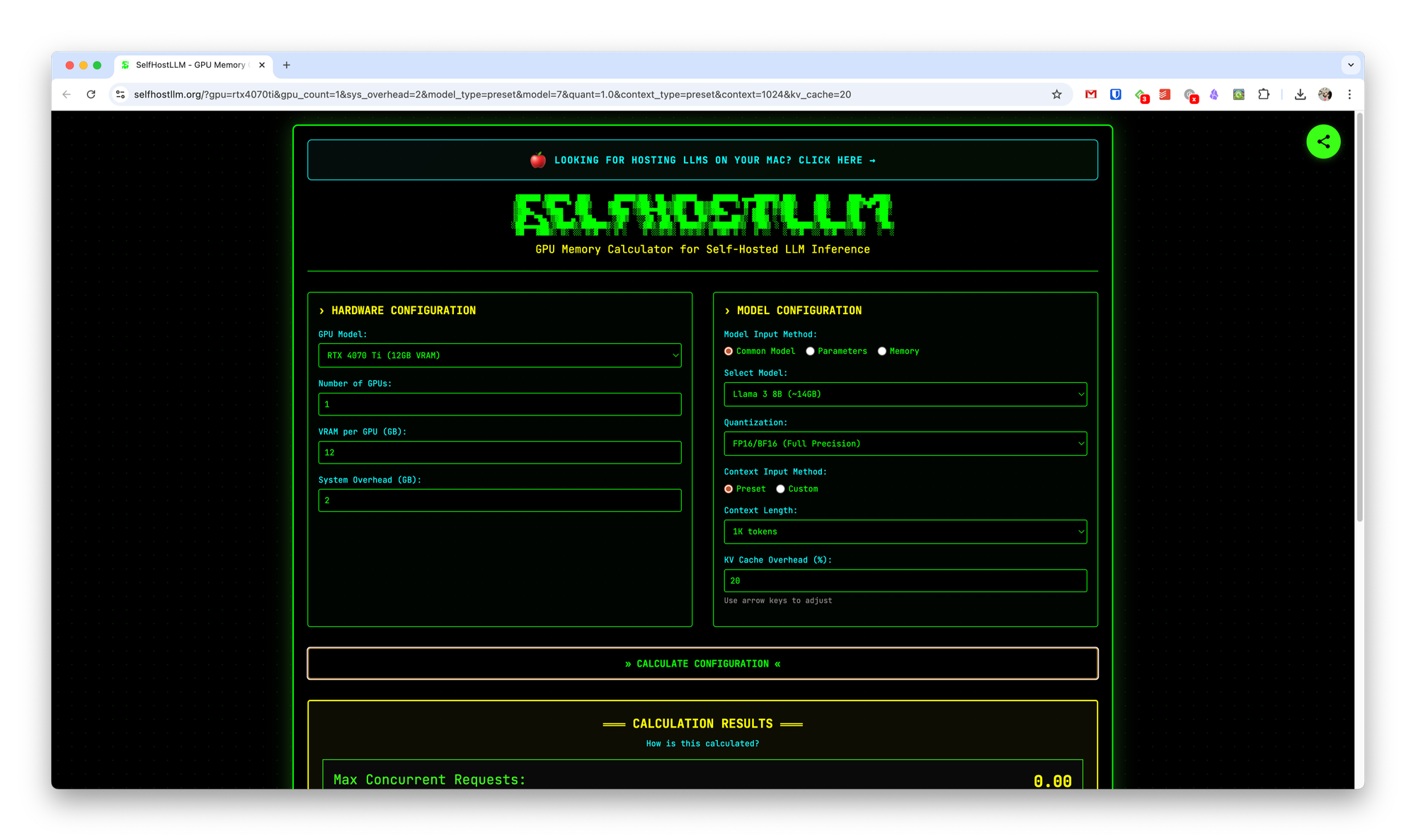
SelfHostLLM lets you check whether your GPU has enough power to run an LLM such as Llama or Mistral, and it calculates the optimal configuration for the model you choose.
Running a neural model on your own computer has become far easier than when they first appeared. That said, it still often requires a powerful GPU setup to run them correctly. How can you be sure your PC can handle the next ChatGPT‑style model?
You can use the SelfHostLLM website, which helps you determine the required GPU memory and the number of simultaneous LLM requests you can handle when deploying the models locally. The site supports Llama, Qwen, DeepSeek, Mistral, and many others.
How it works
- On the left‑hand side of the page, enter the specifications of your current GPU(s).
- On the right, choose the desired LLM model and its parameters.
- Click Calculate configuration.
- You’ll receive a report telling you whether your hardware will be sufficient, and if so, how many concurrent requests you can run safely.
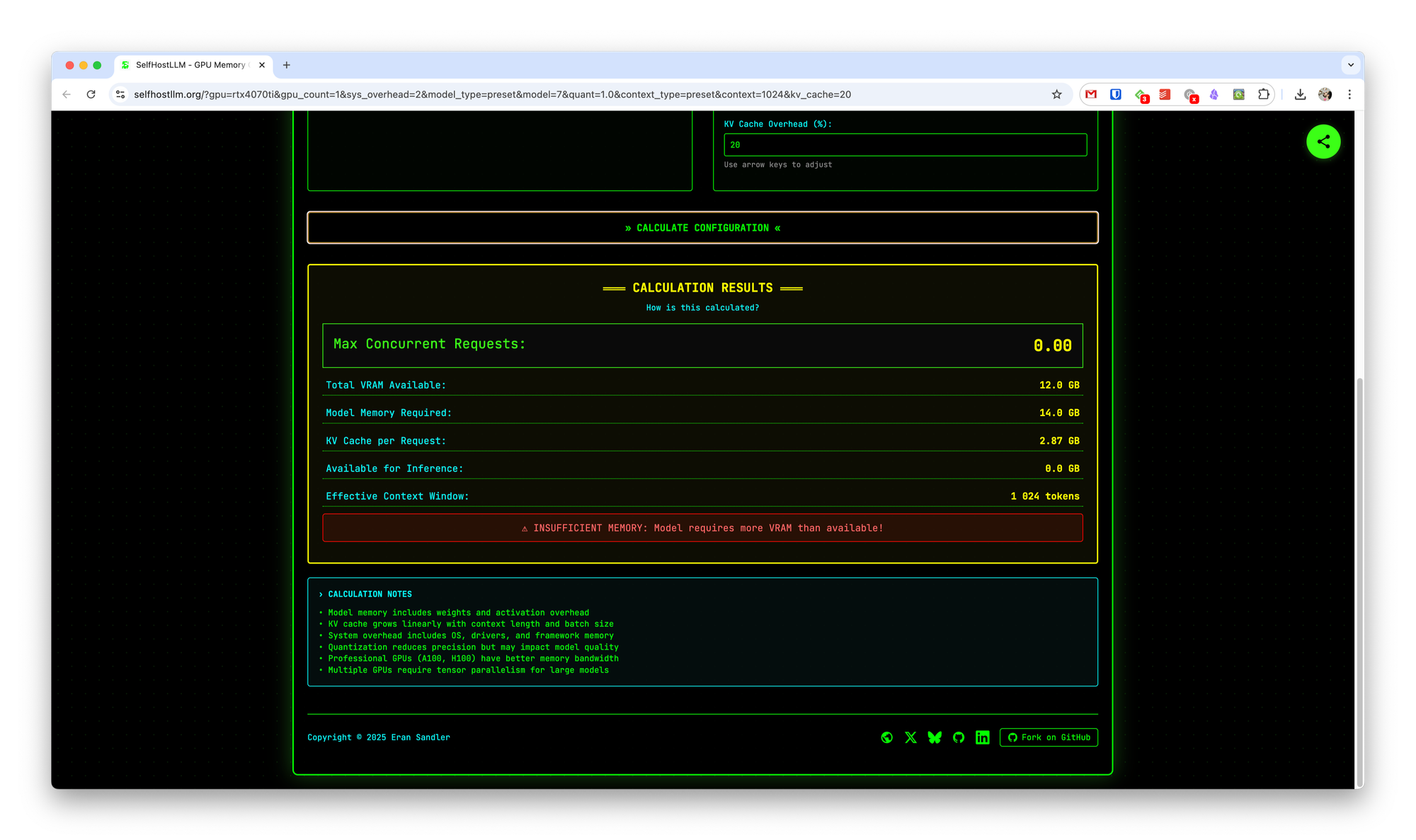
This quick test can save you time and money by letting you know in advance if you need to upgrade your GPU or adjust your deployment strategy.